

📝 Blog Summary
Adding conversational AI to a legacy telecom environment is a massive architectural shock. You are no longer just proxying signaling; you are anchoring real-time media, transcoding streams, and holding open WebSockets.
This blog explores the operational pitfalls of a SIP AI voice deployment, from avoiding nasty codec mismatches to building a carrier-grade orchestration layer that keeps your network stable.
If you try to wire a generative AI model directly into a legacy SIP trunk, you are going to break your network.
Telecom architects are used to proxying signaling. But the moment you add a voicebot into the mix, you aren’t just passing SIP headers around anymore. You are suddenly forced to anchor live media, transcode audio streams on the fly, and hold open persistent WebSockets to public cloud LLMs.
Whether you are upgrading an AI voice contact center SIP trunk or rolling out intelligent agents across a global carrier network, the standard PBX playbook no longer applies.
Here is what actually happens to your infrastructure when you inject AI into the media path, and how to architect your way out of the bottleneck.
The Reality of Integrating AI into the Media Path
Adding an AI agent to a live call completely rewrites your RTP flow. It introduces immediate capacity and routing hurdles that static dial plans simply cannot handle.
In a normal SIP setup, your proxy (like Kamailio or OpenSIPS) handles the signaling, and the RTP media flows directly between the caller and the human agent. When you introduce a SIP AI voice deployment, you break that direct path.
The media must now hairpin (or “trombone”) through a gateway server that forks the audio to the AI engine for speech-to-text processing. You are doubling the network hops for a single call.
The biggest operational trap happens during call transfers. Say your AI bot successfully qualifies a lead and transfers the caller to a human agent. If your architecture doesn’t cleanly rebuild the media path, you will hit these critical failures:
- RTP Port Exhaustion: The AI node remains awkwardly anchored in the middle of the RTP stream, listening to a conversation it’s no longer participating in. Across thousands of calls, this instantly drains your server’s port capacity.
- Audio Latency: Every node the RTP stream touches requires a jitter buffer. Keeping an unnecessary AI gateway anchored in the path introduces noticeable audio delay to the human-to-human conversation.
- The Fix: Your orchestration layer must be explicitly programmed to issue a proper SIP REFER or Re-INVITE the millisecond the AI finishes its job, tearing down the WebSocket and dropping the AI node out of the media path.
Resolving Codec Mismatches Between AI and SIP Trunks
Your SIP trunk provider wants to save bandwidth. Your AI model wants maximum audio fidelity. This creates a massive clash at the network edge.
Most conversational AI and speech-to-text engines need to hear the difference between “s” and “f” clearly to determine user intent. Standard telecom carriers, however, usually compress the audio to save data.
If you feed a raw G.729 stream directly into an AI engine, the bot will constantly ask the user to repeat themselves, creating a miserable customer experience.
Your Session Border Controller (SBC) or media server must transcode that carrier audio into an HD format on the fly before streaming it up the WebSocket.
Integrating AI Voice into an IMS Core (Without Breaking Things)
The IP Multimedia Subsystem (IMS) is the rigid, highly standardized backbone of modern VoLTE and 5G networks. You cannot bypass its rules. In an enterprise PBX, you can hack together a dial plan to forward calls to a script. In an AI voice IMS architecture, doing that violates the core routing topology.
To do this correctly, your AI gateway must be deployed as a standard SIP Application Server (AS). It interfaces with the Serving-CSCF (S-CSCF) via the ISC interface, playing by the exact same signaling rules as a legacy voicemail system.
Instead of hardcoding routing logic into your core switches, you manage the flow via the Home Subscriber Server (HSS).
By configuring Initial Filter Criteria (iFC), the network automatically triggers the AI Application Server based on predefined subscriber profiles.
This allows you to smoothly intercept specific traffic and cleanly fail back to the legacy PBX if the AI engine returns a 503 error.
💡 Expert Tip
A standard SIP OPTIONS ping is completely useless for monitoring an AI voice node. The SIP stack will happily reply with a “200 OK”, keeping your NOC dashboard green, even if the backend WebSocket connection to the LLM is severed.
You must implement synthetic monitoring that places dummy calls, measures the AI’s time-to-first-byte (TTFB) audio response, and triggers a real alert if the conversational latency exceeds 1.5 seconds.
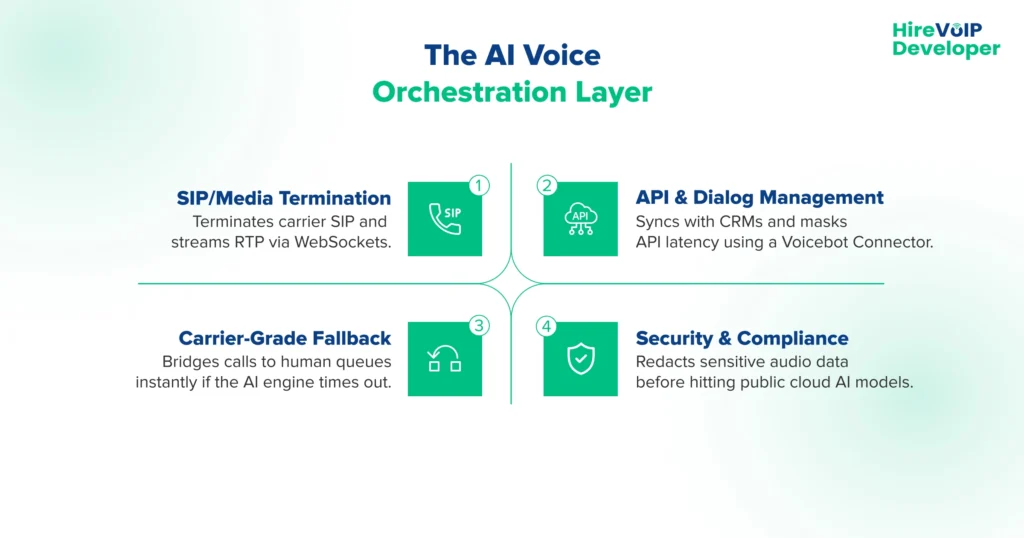
The Voice Bot Orchestration Layer
This is the most critical piece of your entire AI voice SIP integration. You don’t just need an LLM; you need an orchestration layer. This sits directly between your SIP edge and your AI engines, acting as the absolute technical authority for the session.
Bridging the SIP-to-WebSocket Gap
When a call hits the network, the orchestrator terminates the SIP/RTP connection and converts the audio into a real-time WebSocket stream. This is where tools like Ecosmob’s Voicebot Connector are super helpful. It natively handles this heavy translation layer, acting as a high-performance bridge between your legacy SIP trunks and modern conversational AI engines, so you don’t have to build custom WebRTC gateways from scratch.
API Workflows and Latency Masking
The orchestrator manages the silence. If the AI needs to query a backend CRM to check an account balance, the orchestrator handles that API call. If the CRM is slow and takes four seconds to respond, the orchestrator instantly injects filler audio (“Let me pull up your file…”) back into the SIP stream to mask the latency and prevent the caller from hanging up.
Carrier-Grade Failover & L1 Automation
Cloud APIs go down. When the AI engine fails to respond, the orchestrator immediately executes L1 automation logic. It bridges the SIP voice AI call straight to a live human queue, passing along the session data so the human agent knows exactly where the bot failed.
Healthcare Compliance and Data Redaction
You cannot stream raw, unredacted patient calls to a public OpenAI endpoint. The orchestration layer acts as a security firewall. It scrubs and redacts sensitive PII (Personally Identifiable Information) or PCI data from the audio stream before the transcription ever hits the external AI provider.
Capacity Planning Without Over-Provisioning
You cannot capacity plan for an AI deployment using your standard SIP proxy metrics. Transcoding media and managing active WebSockets burns through compute resources at an entirely different scale.
The DSP Compute Trap
Routing a SIP INVITE takes almost zero CPU. Converting an incoming compressed RTP stream into a JSON-wrapped WebSocket payload requires heavy Digital Signal Processing (DSP). If you calculate your hardware needs based on historical SIP traffic, your servers will melt during peak hours.
Decoupling the Control and Media Planes
If you run your signaling proxy and your AI media transcoding engine on the exact same bare-metal server, a sudden spike in voicebot calls will peg your CPU at 100%. This causes the server to drop SIP signaling packets for everyone else, triggering a cascading network outage. You must separate them.
Dynamic Container Auto-Scaling
The only way to survive high-volume AI voice traffic is strict separation and elasticity. Keep your lightweight SIP signaling proxies highly available in a static cluster. Then, containerize your media gateways and deploy them in auto-scaling groups that spin up or down based entirely on real-time CPU utilization, not active call counts.
Adding generative AI to your telecom core is fundamentally an orchestration problem, not a simple routing trick.
If you just force your legacy PBX to blindly forward calls to an API, you are going to destroy your media path, exhaust your server ports, and deliver a robotic, high-latency experience to your callers.
By respecting the rigidity of the IMS core, managing codec transcoding at the network edge, and decoupling your media plane for auto-scaling, you can deploy AI automation that handles enterprise volume without breaking a sweat. You just need to build the orchestration layer correctly the first time.
Ready to architect a zero-latency AI voice integration? Consult our SIP experts today!