

📝 Blog Summary
Scaling VoIP isn’t just about adding servers; without the exemplary architecture, traffic spikes and multi-region growth can cause dropped calls and operational chaos. This blog shows how a carrier-grade IMS infrastructure ensures predictable performance, handles peak traffic, addresses bottlenecks, and accelerates compliant deployment, keeping your platform reliable and ready for growth.
Every VoIP platform appears stable when traffic is predictable, and customers are willing to tolerate occasional glitches. The real stress test begins when the business starts scaling faster than the infrastructure was ever designed to support.
Dropped calls during peak demand, uneven call quality across regions, delayed enterprise onboarding, and long troubleshooting cycles don’t occur in isolation; they quietly compound into revenue leakage and brand erosion. For leadership teams, these aren’t engineering annoyances; they become churn drivers, growth blockers, and trust deficits that are hard to reverse.
A thoughtfully designed IMS (IP Multimedia Subsystem) VoIP architecture provides businesses with the control, isolation, and operational predictability required to serve demanding customers without constantly sacrificing stability for growth.
Moving toward IMS Infrastructure for VoIP is less about adopting carrier standards and more about removing the architectural friction that limits expansion.
So why do they begin to fail as businesses grow, and how should VoIP platforms architect a carrier-grade IMS infrastructure instead? Let’s understand.
How Can VoIP Platforms Design and Build a Carrier-Grade IMS Infrastructure?
VoIP platforms reach a point where flexibility becomes fragile. At this stage, enterprise VoIP solutions become essential to enforce control, predictability, and operational discipline at scale.
In practice, this level of discipline is achieved through a carrier-grade IMS infrastructure that enforces consistent standards for session establishment, management, and evolution as the platform grows.
A well-designed IMS VoIP architecture starts with clear architectural boundaries that prevent signaling chaos and operational ambiguity.
Here is a step-by-step approach that provides clarity for teams implementing IMS VoIP infrastructure while maintaining architectural integrity.
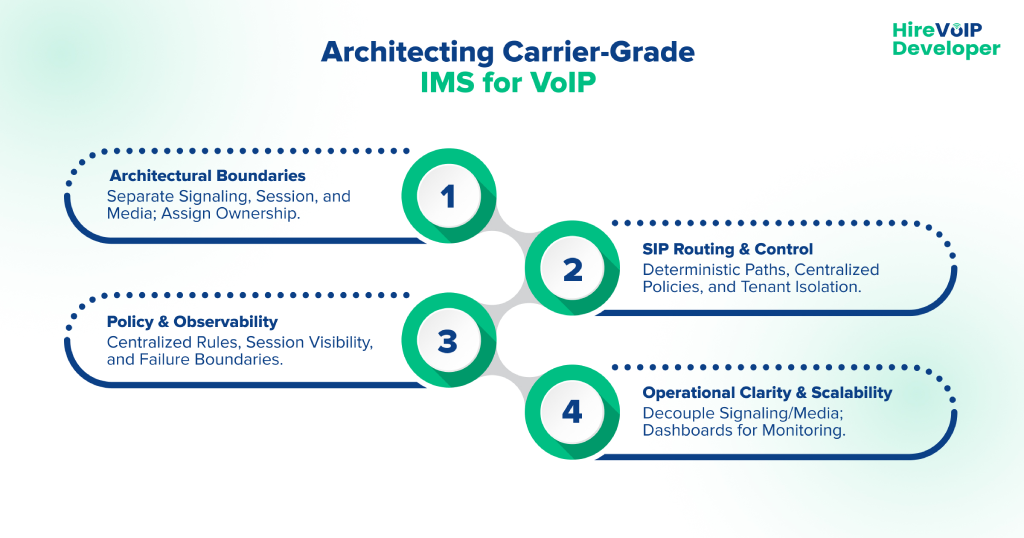
Step 1: Define Clear Architectural Boundaries
- Separate signaling, session control, and media layers.
- Assign ownership of session state independently from application logic.
- Ensure that service features do not interfere with core call flows.
Step 2: Implement Structured SIP Routing and Session Control
- Design deterministic SIP routing paths.
- Enforce session handling through centralized policies.
- Enable tenant- and service-level isolation to ensure predictable behavior.
Step 3: Embed Policy, Control, and Observability
- Centralized policy evaluation for call admission and routing.
- Session-level visibility for deterministic troubleshooting.
- Controlled extensibility to prevent logic sprawl.
- Define failure boundaries to localize impact.
- IMS-based policy enforcement also prevents third-party app integration in VoIP from bypassing session control and creating hard-to-trace production issues.
Step 4: Ensure Operational Clarity and Scalability
- Decouple signaling decisions from media execution.
- Maintain a clear separation between the control and media planes.
- Provide observability dashboards to monitor session health in real-time.
Following these steps ensures that IMS infrastructure for VoIP platforms behaves predictably, scales efficiently, and supports evolving business and technical requirements.
When Should VoIP Platforms Transition from Scaling SIP Servers to IMS?
Scaling SIP servers can work in the early stages of a VoIP platform, but as traffic grows, the limitations become clear. Many of these challenges stem from VoIP scalability traps that only surface under real production load. Comparing SIP server scaling with IMS infrastructure for VoIP across time and growth stages makes the decision tangible.
Let’s compare:
Recognizing these stages early makes it clear that waiting too long to adopt IMS infrastructure for VoIP is not just a technical risk; it directly impacts service reliability, operational efficiency, and customer trust. Platforms that proactively transition to a carrier-grade IMS VoIP architecture can handle peak traffic predictably, accelerate feature rollouts, and expand internationally without disruption.
What Are the Consequences of Delaying IMS Adoption Until After Traffic Spikes?
Delaying the implementation of a carrier-grade IMS VoIP architecture can create cascading issues that affect platform operations, business outcomes, and regulatory compliance.
Understanding these consequences across multiple dimensions helps you make proactive, informed decisions rather than reacting under pressure.
The main consequences include the following:
1. Operational/Technical Risks
At the business level, these challenges translate into the following risks:
- Signaling Overload and Call Instability: Without IMS, SIP servers struggle to handle peak traffic, resulting in dropped calls, delayed setup, and unpredictable session behavior.
- Operational Complexity and Troubleshooting Delays: Limited session-level visibility makes issue diagnosis and resolution reactive and time-consuming, increasing downtime.
- Feature Integration Bottlenecks: Adding new services without IMS risks destabilizing existing call flows, slowing innovation, and system evolution.
- Impact on IVR and Call Flows: Without a carrier-grade IMS VoIP architecture, IVR experiences call-flow failures and inconsistent routing during traffic spikes.
2. Strategic/Business Risks
From a strategic perspective, the implications typically surface as:
- Customer Churn and Revenue Impact: Dropped calls and inconsistent service degrade customer trust, especially among enterprise clients, directly affecting retention and revenue.
- Time-to-Market Delays: Operational inefficiencies slow the rollout of new features and enterprise services, giving competitors an advantage.
- Brand Reputation Risk: Repeated service issues during critical periods undermine credibility and market perception.
3. Compliance & Regulatory Risks
As systems scale and oversight weakens, the following compliance risks arise:
- Regulatory Non-Compliance: Without IMS, enforcing lawful interception, data retention, and emergency call-handling standards becomes difficult.
- Audit and Reporting Challenges: A lack of centralized control and session visibility slows or delays regulatory reporting, or makes it incomplete.
- Legal and Contractual Exposure: Enterprise clients and international operations require guaranteed service and compliance, which a non-IMS architecture cannot reliably provide.
By analyzing the consequences across these three dimensions, Operational/Technical, Strategic/Business, and Compliance/Regulatory risks, it becomes clear that delaying IMS infrastructure for VoIP adoption is more than a technical decision.
Proactive implementation of a carrier-grade IMS VoIP architecture ensures predictable performance, scalable operations, regulatory compliance, and long-term business resilience. Recognizing these risks early allows platforms to scale safely, maintain enterprise trust, and protect market reputation.
How to Design an IMS Architecture That Sustains Peak International Traffic Without Call Drops?
Handling peak international traffic is one of the toughest challenges for VoIP platforms. Even well-architected SIP clusters can falter under unpredictable spikes, multi-region routing, and varied device behaviors.
Dropped calls, inconsistent quality, and slow session setups not only frustrate customers but also create operational chaos and threaten enterprise trust. This is where a thoughtfully designed IMS VoIP architecture becomes critical; it ensures that the platform can scale globally while maintaining reliability and service quality.
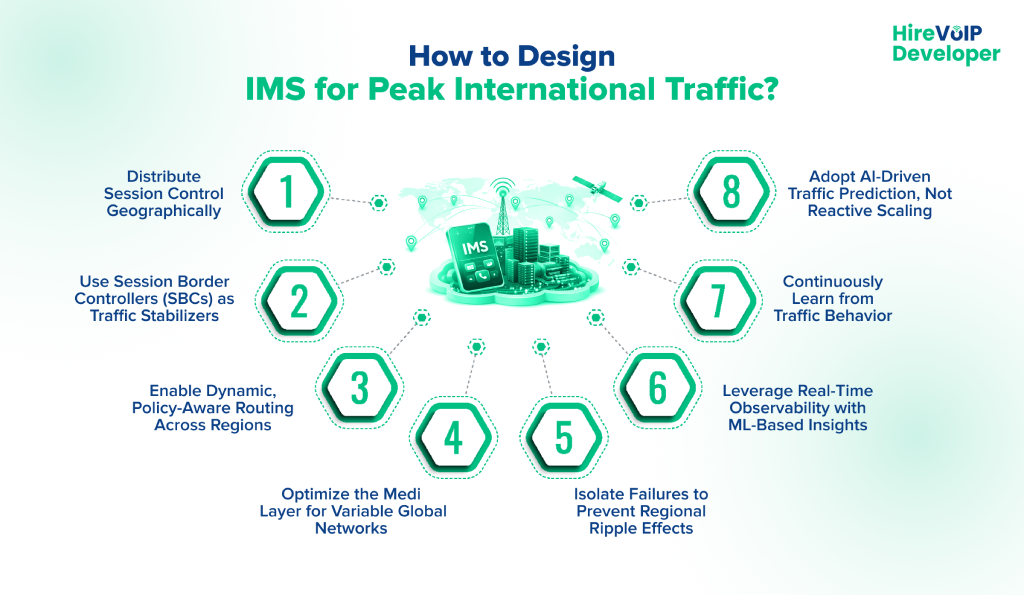
Key design considerations include:
- Distribute Session Control Geographically: Place IMS control elements closer to traffic sources to prevent international spikes from overloading a single region or causing global signaling delays.
- Use Session Border Controllers (SBCs) as Traffic Stabilizers: SBCs secure cross-border signaling, normalize interoperability issues, and shield the IMS core from malformed traffic and overload during peak demand.
- Enable Dynamic, Policy-Aware Routing Across Regions: Intelligent routing decisions ensure international calls follow optimal paths based on real-time network conditions rather than static rules.
- Optimize the Media Layer for Variable Global Networks: Adaptive codecs, bandwidth management, and media redundancy maintain call quality despite fluctuating international link conditions.
- Isolate Failures to Prevent Regional Ripple Effects: Proper isolation ensures a traffic surge or outage in one geography does not cascade into other regions or tenants.
- Leverage Real-Time Observability with ML-Based Insights: Session-level telemetry, combined with anomaly detection, identifies early warning signs of congestion before users are affected.
- Continuously Learn from Traffic Behavior: ML models refine routing, capacity planning, and resource allocation over time, making the IMS platform more resilient with every peak event.
- Adopt AI-Driven Traffic Prediction, Not Reactive Scaling: AI and ML integration in VoIP helps forecast congestion patterns and reroute sessions before call quality degrades or drops occur.
Designing an IMS infrastructure for VoIP capable of handling peak international traffic requires more than scaling SIP servers; it demands a holistic architecture that combines distributed session control, centralized policies, optimized media handling, and real-time observability.
Platforms that implement these design principles can deliver reliable, high-quality global service, prevent call drops, and maintain customer trust even during extreme traffic conditions.
Where Do Most IMS Performance Bottlenecks Occur in Production?
Even the most carefully designed IMS VoIP architecture can reveal weaknesses in real-world conditions. Peak traffic, international calls, and complex service features often expose bottlenecks that impact both reliability and user experience. Understanding where these occur helps platforms proactively optimize their IMS infrastructure for VoIP.
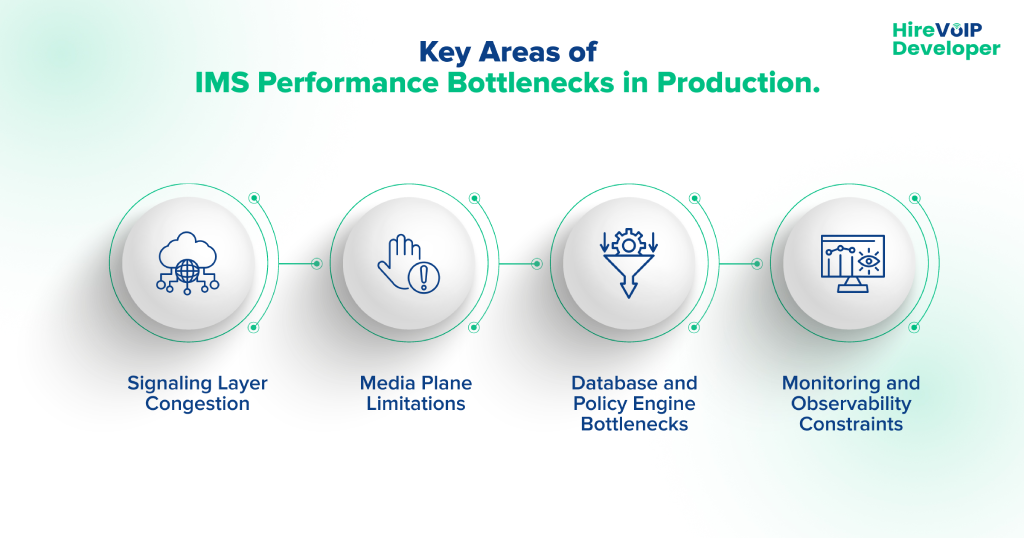
The primary production bottlenecks to watch out for include:
-
Signaling Layer Congestion
High call volumes and centralized policy evaluation can overwhelm SIP controllers. This results in delayed session setup, increased retries, and unpredictable signaling behavior.
Distributing signaling nodes and optimizing routing logic reduces hotspots and improves call reliability.
-
Media Plane Limitations
Media gateways can reach capacity during peak or international traffic, resulting in jitter, packet loss, and dropped calls. Lack of redundancy or adaptive media handling worsens the impact.
Isolating media handling from signaling and implementing redundancy ensures consistent call quality.
-
Database and Policy Engine Bottlenecks
Centralized subscriber databases or policy engines often become choke points under heavy load. Slow call admission or feature activation impacts reliability and responsiveness.
Efficient caching, session management, and distributed policy engines can prevent bottlenecks before they affect call volume.
-
-
Monitoring and Observability Constraints
-
Limited real-time telemetry and high-latency metrics pipelines prevent early detection of congestion. Predictive insights are often unavailable, turning minor spikes into cascading failures.
Session-level observability and predictive analytics are critical to proactively managing traffic and maintaining uptime.
Production bottlenecks typically occur in the signaling, media, database, and observability layers, and proactively addressing these areas is essential to a robust IMS VoIP infrastructure.
Platforms that are designed for these constraints can sustain peak traffic, maintain call quality, and ensure reliable international service.
How Can We Reduce Time-to-Market While Building a Compliant IMS Core?
Launching a VoIP platform quickly while ensuring regulatory compliance is one of the toughest challenges for telecom businesses. Delays in deployment not only slow revenue recognition but also risk losing enterprise clients who demand fast, reliable, and compliant service.
Building a carrier-grade IMS VoIP architecture from scratch can feel overwhelming, but adopting strategic approaches can dramatically accelerate time-to-market without compromising compliance or quality.
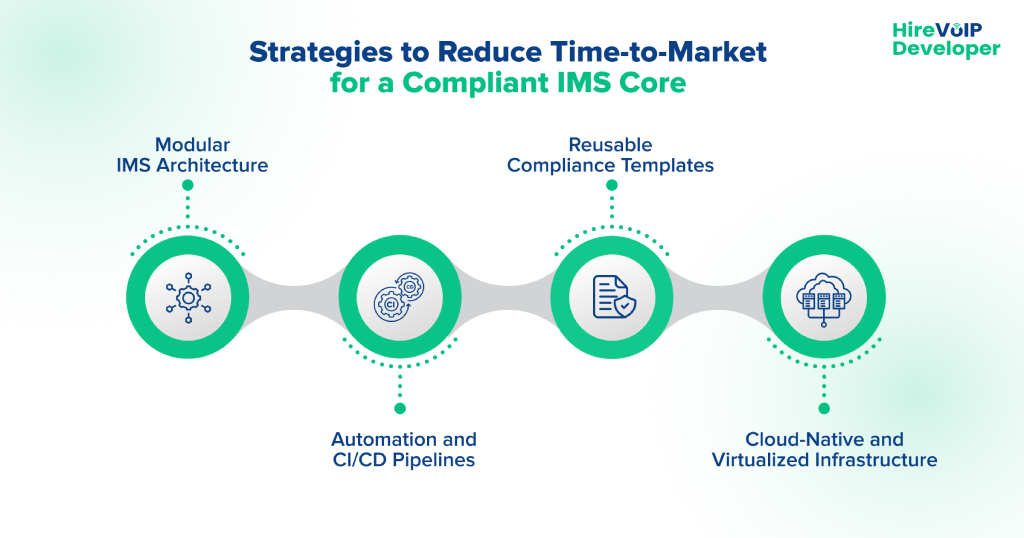
The key strategies to accelerate IMS deployment include:
1. Modular IMS Architecture
- Separate session control, media handling, and policy engines to enable parallel development.
- Plug-and-play modules make it easier to integrate new features without destabilizing core services.
- Modular architecture supports incremental compliance verification for each layer.
2. Automation and CI/CD Pipelines
- Implement automated testing for call flows, signaling, and policy enforcement.
- Continuous Integration/Continuous Deployment (CI/CD) pipelines streamline the rollout of code and configuration changes.
- Automated compliance checks ensure regulatory adherence without slowing development.
3. Reusable Compliance Templates
- Templates for lawful interception, emergency call routing, and data retention reduce the need for custom coding.
- Standardized configuration prevents compliance gaps across regions.
- Built-in compliance workflows enable rapid auditing and reporting.
4. Cloud-Native and Virtualized Infrastructure
- Use virtualized IMS components to deploy or scale without hardware delays.
- Cloud-native orchestration allows rapid spin-up of regional nodes.
- Elastic resources help maintain performance during peak loads while ensuring regulatory separation of regions.
Reducing time-to-market for a compliant IMS core is not about cutting corners; it’s about innovative architecture, automation, and reusability. By adopting modular design, CI/CD pipelines, pre-built compliance templates, and cloud-native deployments, VoIP platforms can launch faster, maintain regulatory compliance, and stay ahead in a competitive market.
Wrapping Up
VoIP platforms can hit bumps, calls drop, onboarding slows, and traffic spikes create chaos. The solution? An innovative IMS VoIP architecture that handles growth without breaking a sweat.
With the proper IMS infrastructure for VoIP, you don’t have to worry about glitches slowing you down or losing customer trust. And you don’t have to do it alone. Hire VoIP Developer brings the know-how to build and manage carrier-grade IMS systems, so your platform runs smoothly, scales easily, and keeps your users happy, no stress, no surprises. Get in touch today!
FAQs